
For a modern defender, tracking individual AI model brands is a distraction. The real threat is a class of capabilities evolving monthly. Knowing the class is more useful than tracking the brands.
Public conversation about AI driven cyber threats tends to focus on individual models, often Mythos. This is useful for headlines and unhelpful for defenders. The relevant question is not which specific model an adversary will use. It is which class of capabilities they will have access to, and how those capabilities are evolving across the entire ecosystem of frontier and open weight models.
The Benchmark That Started the Conversation
On a single public benchmark, Mythos produced 181 working exploits to the best publicly available model's two. The gap is not a rounding error. It is the entire architecture of the problem.
The Firefox 147 benchmark tests the specific capability defenders care about most: the autonomous identification and weaponization of real flaws in real software. It has three properties that make it more useful than most. It is publicly described, with methodology disclosed. It is repeatable, against a fixed software target. And it tests real world code.
A 90 times gap on this benchmark is not a model versus model preference question. It is a defensive capability versus defensive capability question. And it has a direct answer for every security team still calibrating its programme around publicly available tooling.
The Four Cohorts Worth Distinguishing
Defenders who track model names will always be wrong by next quarter. Defenders who track cohorts will always be right.
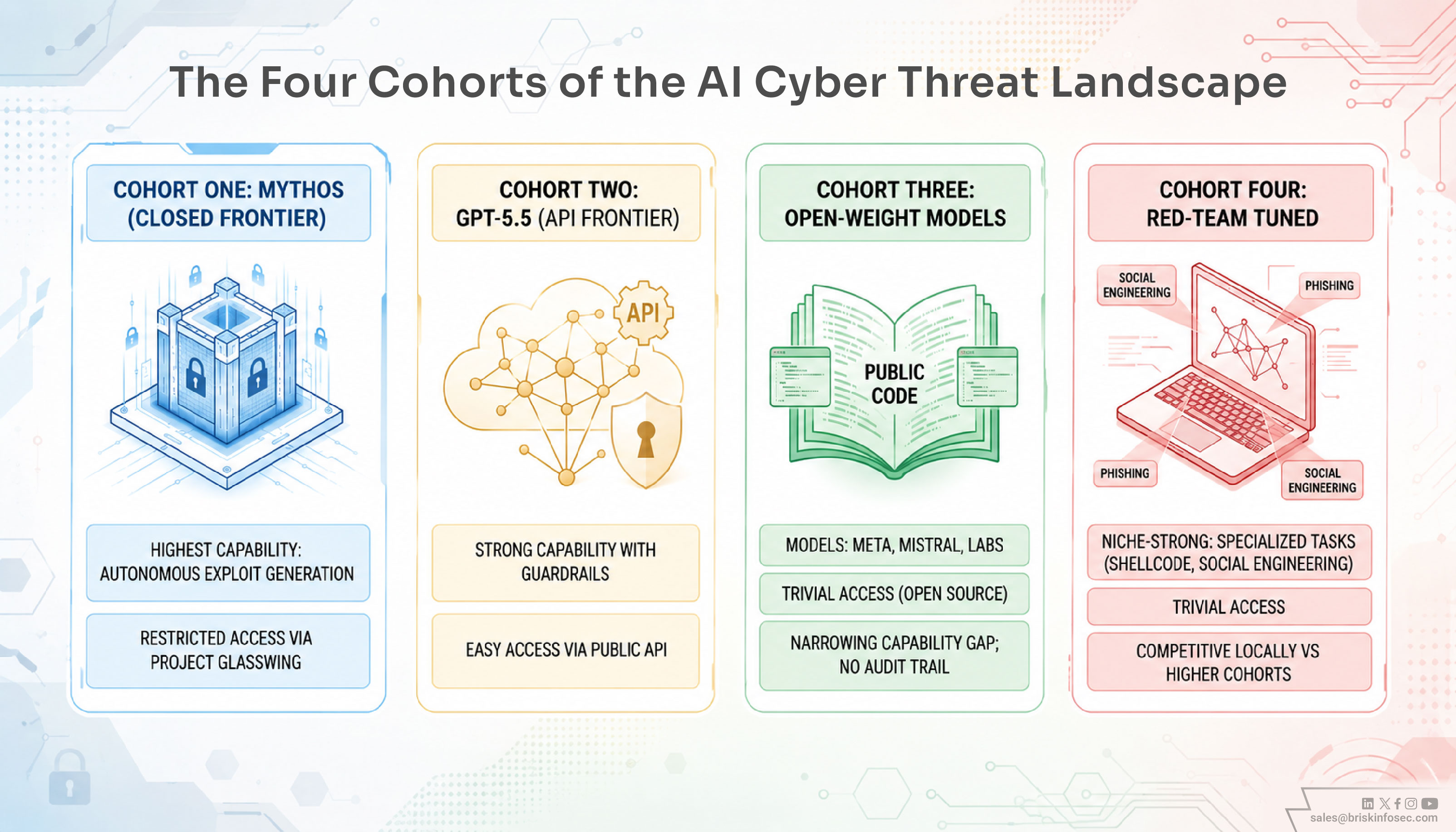
- Cohort One: Frontier Closed Access
Mythos sits here. Highest demonstrated capability, tightly controlled access, restricted to vetted consortia through Project Glasswing. Currently the most capable autonomous vulnerability discovery and exploit generation system in the public record. - Cohort Two: Frontier API Access
GPT-5.5 from OpenAI sits here. Strong general-purpose capability, available to anyone with API access, with safety guardrails that adversarial researchers actively work to circumvent. High capability, low access friction. - Cohort Three: Open Weight High Capability
Models whose weights have been publicly released, including several from Mistral, Meta, and a handful of well-resourced labs. Capability lags Cohort One, but the gap is narrowing monthly. No access controls. No audit trails. - Cohort Four: Red Team Fine Tuned
Open weight models fine-tuned by adversarial researchers for specific cybersecurity tasks. General capability is lower, but for specific niches like phishing generation, shellcode optimisation, and social engineering content, they are competitive with models two cohorts above them. This includes specialized vernacular phishing models tuned for Indian language regional dialects, which bypass traditional filters with high efficacy.
The Asymmetric Threat Matrix
| Capability | Mythos C1 | GPT-5.5 C2 | Open-Weight C3 | Red-Team Tuned C4 |
|---|---|---|---|---|
| Autonomous flaw discovery | Highest | High | Moderate | Variable |
| Chain of flaws reasoning | Highest | High | Moderate | Low |
| Working exploit generation | Highest | High | Moderate | Niche strong |
| Phishing content quality | Excellent | Excellent | Good | Excellent in niche |
| Access by an adversary | Restricted | Easy via API | Trivial | Trivial |
| Detection by defenders | Hard, low signal | Possible via API logs | Impossible | Impossible |
Why the Access Row Matters More Than Any Other
Reading the table above, the row that should disturb every defender is not capability. It is access.
Mythos is the most capable model, but adversary access is hardest. Open weight and red team fine-tuned models are less capable but trivially accessible. The honest threat assessment for most enterprises is that they are more likely to face an open weight or fine-tuned adversary than a Mythos class adversary directly.
The defensive disciplines, however, are identical. A posture hardened against Mythos class chain of flaws attacks is hardened against the entire cohort spectrum. Building for the most capable adversary protects against every cohort below it.
What the Ninety Times Gap Actually Means
Three operational implications follow directly from the capability gap. Each one is worth sitting with carefully.
- Tool parity is a defensive trap. The gap will not be closed by purchasing a single product. The defensive answer is layered defence: faster patching, smaller attack surface, better instrumentation, and rehearsed response. These compound over time. A 90 times capability gap does not change the math on the basics.
- Time and discipline are the remaining levers. The disciplines that matter most like continuous testing, attack surface compression, AI augmented detection, and rehearsed incident response are independent of which model an adversary is using. They work against Cohort One. They work against Cohort Four. They compound regardless.
- Human expertise becomes more valuable, not less. The defensive moves that matter are the ones requiring judgement, threat modelling, and chain reasoning. Those remain stubbornly human led, even with AI augmentation. Vendors selling autonomous defence that removes humans from the decision loop are either misrepresenting the technology or pricing for malpractice insurance that does not yet exist.
What the Gap Does Not Mean
It does not mean defence is hopeless. It does not mean every enterprise will be breached. It does not mean publicly available AI tooling is useless to defenders.
Public models remain genuinely useful for triage, hypothesis generation, log analysis, and the moderately complex tasks that consume most of a SOC analyst's working day. The 90 times gap describes the upper bound of offensive autonomy. It does not describe the operational reality of every attack.
The defenders who treat the gap as motivation rather than despair arrive at the same conclusion every previous capability shift has produced: the ones who do the unglamorous basics, faster and more consistently than their peers, win the decade.
How the Threat Will Evolve in the Next Twelve to Twenty-Four Months
Three trajectories matter and none of them points toward a simpler threat landscape.
Open weight capability will continue closing the gap with Cohort Two. Models that sit at Cohort Three today will have Cohort Two capability within 12 to 18 months. Fine tuning techniques will continue making specific task adversarial models more dangerous in their niches. And defensive AI tools available outside Glasswing will improve but not at the pace of offensive tools, because the economic incentives do not point in the same direction.
The net effect is that the threat geometry will broaden, not narrow. More adversaries will have access to higher capability. The perimeter of serious threat will expand from nation state and sophisticated criminal groups toward a much wider population of technically capable operators.
The defensive strategy that survives this trajectory is not one that bets on tool parity catch up. It is one that invests in the operational disciplines that compound regardless of which cohort the adversary is drawing from.
The Practical Takeaway for Every Security Team
Track the cohort, not the brand. The brand will be wrong by next quarter. The cohort will still be accurate in two years.
Maintain a four-cohort mental map of the AI threat landscape. Update its quarterly. Brief the board on the gradient of capability across cohorts and the operational implications of each.
The 30 Second Boardroom Script
Our adversaries are no longer writing exploits manually; they are using highly accessible, unmonitored open weight AI models to test our perimeters continuously. We cannot buy our way out of this with a new tool. Instead, we are focusing our efforts on continuous testing and shrinking our patch deployment windows. That is how we neutralize this speed advantage.
The 90 times gap are a sobering statistic. Treated as motivation rather than despair, it points to the same conclusion every previous capability shift has reached. The defenders who do the unglamorous basics, faster and more consistently than their peers, win the decade. Build the disciplines. Maintain the map. Subscribe to a structured threat intelligence cadence that tracks all four cohorts, not just the one in the headlines.
Tool parity is a fantasy. Discipline parity is the work.
Conclusion
The cyber capability gap between Mythos, GPT-5.5, and open weight models is real, documented, and widening. But the gap between cohorts is not the most operationally important number in this analysis. The most important number is the access row in the comparison table because that is where the realistic threat profile for most enterprises actually lives.
Cohort Three and Cohort Four models are trivially accessible, increasingly capable, and largely invisible to API-level monitoring. They are the adversary most enterprises will face before they ever encounter a Mythos class operator. The defensive posture that handles them handles everything above them in the cohort stack.
Defenders who build for the class will be prepared for whatever ships next. Those who build for the named model will be wrong before the year is out.
FAQ
1. Why are open-weight AI models becoming a major cybersecurity threat?
Open-weight AI models are freely accessible, customizable, and difficult to monitor, allowing attackers to automate phishing, exploit research, and cyber operations at scale.
2. What is the difference between Mythos, GPT-5.5, and open-weight AI models?
Mythos represents restricted frontier-level capability, GPT-5.5 provides controlled API access, and open-weight models prioritize unrestricted deployment and customization.
3. Why does AI model accessibility matter more than capability?
Even moderately capable AI models become dangerous when attackers can access, fine-tune, and deploy them privately without oversight or monitoring.
4. Can enterprises detect attacks generated by open-weight AI models?
Open-weight models operating locally are largely invisible to API-level monitoring, forcing defenders to rely on telemetry, behavioral analytics, and attack surface visibility.
5. How can organizations defend against AI-driven cyber threats?
Organizations should prioritize continuous testing, rapid patching, attack surface reduction, AI-assisted detection, and resilient incident response practices.


